The launch of the iPhone a decade ago in combination with the app-store-based distribution model set in motion the conditions for mobile applications to become mainstream in an easy, user-friendly way. However, it was since even before this development that colleges and universities have seen both the potential, and the necessity, of adopting mobile applications to better serve their student populations. Our newest research affirms the growing pervasiveness of mobile technologies on US campuses.
For the first time, we are publishing data on the mobile apps that schools adopt at an institution-wide scale. To appear in this data set, the app must have some official or material connection to a university and be adopted or implemented in such way that it would be useful to a broad user base and contain content or functional capabilities that are relevant to that specific school’s needs (that is, not generic in nature). What we are measuring is the number of mobile apps adopted by institutions, not the number of downloads by individual users nor the number of downloads or popularity of consumer apps among college students.
Types of Mobile Apps
What we found is that over 700 institutions have implemented one or more mobile applications of this type. We clustered the types of apps into these 5 categories based on their primary purpose:
- The “Campus App” – a “one-stop-shop” for information, including information only accessible with a specific student login, typically designed for currently-enrolled students
- Events/News/Alerts/Outreach apps that contain a calendar or content targeted at external audiences including local communities, sports fans, or for recruiting prospective students
- Tour/Map/Transit apps that focus primarily on navigation around campus
- Educational/Student Support apps that focus on serving some direct, unique, educational purpose (largely excluding LMS mobile apps) or student advising
- Dining/Payment apps for displaying cafeteria menus and supporting mobile payment options specific to a given campus
The mobile applications adopted by each institution vary widely. Smaller universities tend to implement a single, single-purpose app. Larger universities tend to implement several apps including a campus app that connects to and integrates with multiple other campus systems.
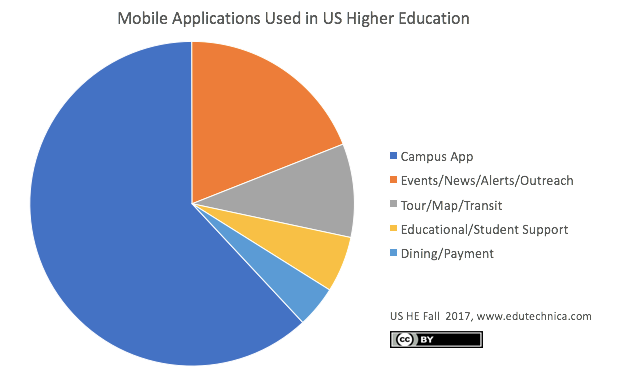
As you can see in the graphic below, the campus app is the category that has experienced the largest adoption in US higher education. Together with apps that support outreach to local communities and prospective students, these two categories encompass more than 75% of all mobile applications. It is worth noting that the mobile applications experiencing the most adoption are largely not focused on meeting purely academic needs, often containing multiple capabilities such as registration, student communities, social media updates, a phone directory, and event calendars. The majority of widely-adopted campus apps also have the ability for individual students to log in to display information relevant to that specific student.
Notable Platforms
Focusing specifically on the campus app category, only a minority of schools self-publish their own app under their own institution’s vendor name even when using an app framework or codebase provided by a consultant, vendor, or open source community. The majority build on top of, or integrate with, one of several major mobile platforms that are branded as being provided by that vendor. OOHLALA and Blackboard Mosaic capture almost half of these type of campus app implementations with DubLabs, Unifyed, and Modo Labs all tied for third-place.
Note: We have adjusted this graphic since the original post to include self-published apps. It is, again, important to be aware that self-published apps are more-often-than-not created by a specialized mobile application development shop or by one of the vendors mentioned above. Most institutions do not develop their own apps.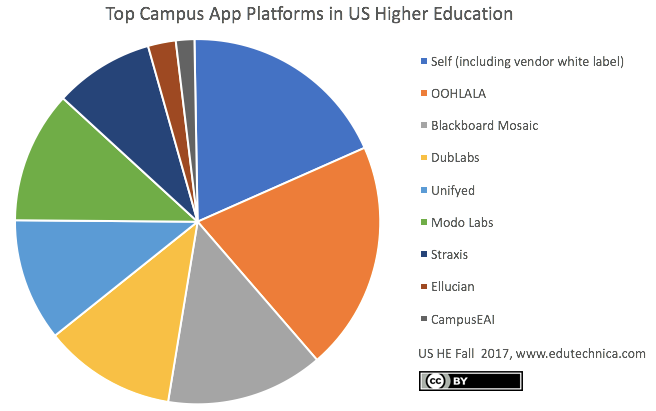
Other popular mobile platforms include Guidebook, which provides a platform that can be used to display relevant information to prospective students and YouVisit, a popular mobile platform for providing virtual tours of campus (including VR tours).
Other Findings
While performing this research, we also came across a number of other findings that relate to mobile strategy on campus.
Quality Matters
Apps that are rated the lowest in each app store are correlated with a poor first experience opening the app, generally caused by a technical glitch or a slow or inconsistent load time. The student expectation is that each app “just works.” Conversely, apps that are rated highly generally feature content that is kept up-to-date and features that are relevant to their needs.
Responsive Design Versus “M dot”
While there has historically been a convention of hosting mobile web content at m dot school dot edu (for example, m.psu.edu), this is a significantly less popular approach than using responsive CSS design on the institution’s regular home page. Most modern mobile phones can correctly render web sites in ways that were not possible in years past. Our recommendation is to design for the default browser on each mobile platform (Chrome for Android and Safari for iOS) and consider Firefox mobile.
Official Apps Versus Unofficial Ones
When searching each app store, it is actually somewhat difficult to distinguish a “real” university mobile app from an unofficial one. While most unofficial apps are written by enthusiastic students or alumni, many appear to be suspicious in nature and built on top of advertising platforms. Our recommendation is that universities should attempt to control their brands however possible to prevent confusion, or worse, while supporting sanctioned innovation.
App Proliferation
Many universities appear to have decentralized funding sources for mobile apps and lack a unified mobile strategy. Particularly among larger universities, this results in multiple official apps that lack consistency or defined purpose. Our recommendation is to differentiate apps based on audience (e.g.: internal vs external) rather than function.
VR (Virtual Reality) Mobile Apps
While many experts have suspected that Virtual Reality would take off in the classroom, VR’s largest impact in higher education appears to be to support virtual campus tours. Using this technology allows potential students to more-fully understand the physical campus experience without the expense of travel.
LMS Apps
Our latest LMS data set suggests that almost all universities are currently running a LMS that supports a corresponding, free mobile app. Unless a school went out of its way to actively promote the LMS mobile app as a core part of the student experience, we did not include it in this report. Generally, we did not find institutional adoption of apps that focused specifically on learning or learning content separately from the LMS app.
Dead Apps
During our research, we found quite a number of broken links to discontinued mobile apps. Blackboard’s recent decommission of Mobile Learn in favor of a pair of separate student and instructor-focused apps, for example, leaves a trail of broken links. Smaller mobile vendors or independent consultants that have ceased operations or gone out of business are also correlated with this condition.
For inquiries, please contact marketdata@clientstat.com