Note: While I generally prefer to keep work and life separate to the extent possible, this is one of those occasions where my professional experience, personal interests, and graduate student coursework happen to intersect. This post reflects neither the thoughts nor opinions of my employer.
Though I found out about it too late to attend, I was excited to learn about the recent University API workshop hosted by BYU. It’s the first time I’ve heard of such an event having a distinct focus specifically on APIs and universities. Thank you to those institutions who are providing some initial momentum here. One of my previous jobs was as a developer who helped educators and software engineers to use APIs to integrate with LMSs, and over the past two years I’ve been fortunate to work for UMUC where I do very much the same on a much more local and meaningful level. Over this time, the team I work on has replaced the university’s home-grown LMS with a commercial one, and in doing so rebuilt and rewired integrations with many new and existing back-and-front-end systems.
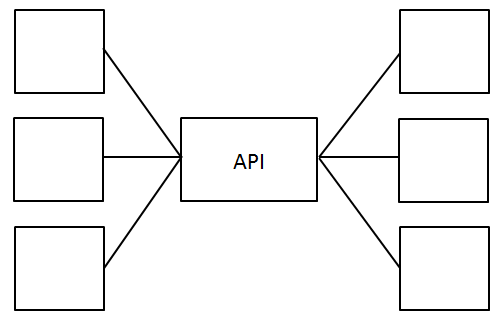
Needless to say, open standards have played a critical role in achieving this vision. But while they help in many ways, they aren’t best-suited for every application that we want to build, and a standards-compliant LMS alone does not an online student experience make. To address these needs, one of my team’s more recent projects has been to develop a REST API that could be used by anyone at the university to build apps. It slurps in data from a whole array of back-end systems – including those that don’t currently and don’t ever plan to support open standards. For example, these APIs can retrieve user profile data from the identity management system, enrollment data from the SIS, and even the balance due from the financial system. By unifying all of these systems behind the facade of an easy-to-use API, other teams around the university (ie: not just “central IT”) have been experimenting with rapid prototypes of apps and portals that will soon modernize a number of random legacy applications and begin to facilitate the creation of new ones.
Previously, getting at this data required clunky point integrations with the SIS, LMS financial, authentication, identity management, and other administrative systems. These integrations often require designing for complexity and specialized skill sets to use each vendor’s API. They are also brittle and prone to breaking with each upgrade, increasing risk and the level of ongoing QA effort required.
By inserting an API into the architecture, we can now provide logged-in users all of these details using simple calls that abstract away the behind-the-scenes complexity. It is enabling us to find ways not only to build new applications but also swap out legacy back-end systems behind the scenes without changing the nature of how these APIs are used on the front-end.
There are many universities including Berkeley, University of Michigan, and University of Washington that have been experimenting with API efforts recently. Perhaps the most interesting ones I’ve come across are the efforts undertaken by BYU and University of Waterloo. Their designs offer (what I think at this time are) the most complete assemblage of useful data aggregated across all of the systems a university would typically use.
Which brings me to my next thought.
What would happen if a university flipped the model of integrating its systems and instead of writing individual connectors to each vendor’s system, the university itself provided a standardized API for each of its vendors to use? This changes the dynamic of the relationship significantly. No longer does a vendor need to ask which SIS or LMS a particular institution uses. Rather, it only needs to know which version of the “campus API” or “university API” it implements. It also means that you don’t need to wait for a specific product to implement a specific version of a specific standard to move forward with an integration. You just write your implementation to the interface using whatever capability a given product offers and in doing so provide a facade that avoids this factor altogether.
Suddenly, universities can become much more flexible in how they can swap in/out, upgrade, and rearrange all of their systems behind the scenes. The overhead of implementing and QAing product integrations decreases by shifting the development responsibility for the integration to each vendor. Vendors benefit from a uniform way to connect to any university that implements the API. Universities become better positioned to supply and control access to application data. Students receive an easier way to access their own data. The API itself then becomes a platform for innovation rather than any specific vendor’s product. Imagine different vendors offering competing course catalogs that adapt to a student’s major, academic progress, and personal interests – or the ability for students to slurp data feeds into any mobile app, not just the one offered by the university. Or imagine an enterprising capstone project team building the cafeteria menu app that your students always wanted but never received high enough priority to build – or even the ability for a student (or adult professional) to register for a specific class using a “Take My Class” button on a professor’s personal blog rather than logging in and searching through the cumbersome UI of most SISs. (Also imagine a university with a business model where you don’t need to become a full-blown student just to audit one class.) This is exciting stuff.
There are many resources to help universities understand APIs better. First, the EDUCAUSE ITANA Constituent Group hosts a subgroup focused solely on APIs and API governance. Kin Lane has written a helpful white paper that describes some of the above university API efforts (and their benefits) in greater detail. (Seriously, consult with him if you consider going down this path.) Finally, the notes from BYU’s recent API workshop are hosted here.
There are also a pair of organizations who appear best-poised to tackle this challenge specifically in a higher-education-focused context. Lingk is a very new startup that is focused on building a SaaS-style product with the ability to interoperate with a number of systems typically used on college campuses and expose their data in different, more-modern ways. Apidapter is a more-established startup that centralizes LTI launch requests within a single management framework so that usage details and error messages can be logged and trended. Apidapter also allows standards-based transactions to be transformed “mid-flight,” sometimes to augment the capability of the standard and other times to pull in additional data from other systems, such as an LDAP server, and adding these as LTI launch parameters before reaching the target system. (Disclosure, UMUC uses Apidapter under-the-covers for some of its LTI-based integrations. This is not a product recommendation. But seriously, it is cool, and you should go check it out.)
In my opinion, administrative systems are one of the greatest limiters of IT agility at colleges and universities specifically because of their complexity and inflexibility, whether real or perceived. Universities will face continued pressures to adapt more quickly to constant change, and an API could provide a stable, unified approach to better support innovation and accommodate IT change more easily so that we can collectively free ourselves from legacy IT challenges. Let’s get to it.
This post written by George Kroner