I’m encouraged to see the conversation about “open” broaden to contexts beyond education recently. The general public seems to have finally become interested and concerned about the open web. Never mind that it took the threat of slowing Netflix and YouTube to a crawl, but it is encouraging nonetheless. It is important, too, to keep debating the actual meaning of open. But it is now increasingly important to begin understanding open in different contexts, the forces that shape open, and how open layers, builds, and interacts with itself.
Open is a powerful concept – a game changer with the ability to disrupt the status quo. Some say that Massive Open Online Courses threaten the core business models of universities. Others affirm that Open Educational Resources threaten the major publishers. But rather than seeing open as a threat, I would like to consider the opportunities that open creates. To paraphrase David Wiley, you never know what you’re going to get when you choose openness – and as history informs us, while change can sometimes be painful, you’re better off to be proactive about it. To be proactive about openness not only necessitates having a pragmatic understanding of what it is and isn’t but also how it has evolved over time.
There are two main contexts within which I see open having matured in educational technology. These are first, open as from the perspective of technologists, and second, open in the eyes of content creators.
Open Software
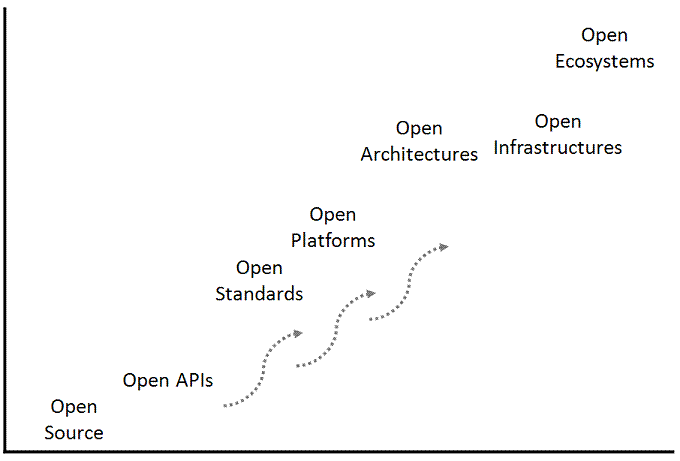
In the first context, the opening of software has its roots in the open source software movement. It begins with providing access to the raw source code that runs a software product or system. This is akin to having the exact measurements and all the steps necessary to recreate a recipe from scratch. Over time, people realized that while having access to the source code to customize educational software was helpful, having standard, reusable hooks to plug into was a better approach, and so open APIs came into existence. Open APIs provided convenient, well-defined ways to hook into educational technology platforms, but integrations built using these APIs were often piecemeal and product-specific in nature. They were not reusable and were prone to breakage when the software was upgraded to a newer version. To overcome these weaknesses, open standards were created as a way to do things in a very uniform way across multiple software products. Standards can’t do everything APIs can do but enable all platforms to achieve a common denominator of a capability. You can think of them as “write once, run anywhere” – which is in practice often the case. While there are still some glitches, open standards have gotten us to a much better place than before. Standards also began to create efficiencies and break down barriers between products. If you wanted to plug once piece of software into many other software products, all you needed to do was write one, standards-compliant integration rather than an individual one for each other system. Because many products support standards, the same software could be plugged into many others enabling collaboration among users of systems in ways that were previously difficult at best.
Individual products then began supporting whole sets of open standards in addition to APIs. Some of these products were open source, but some were not. And once we reached this level of maturity, software products in my opinion became software platforms. They could connect in well-defined ways on the front-end, back-end, and tail-end with very-little-to-no customization. Often, only configuration of these integrations was necessary. Today, I would consider many popular LMSs that we use to be examples of platforms. But even still, not every LMS supports all standards, and sometimes the specifics of the standards support vary.
Once we can more clearly define complete sets of standards support and clearer expectations of behavior, I would expect open platforms to become part of open architectures. Open architectures will allow us not only to plug things together but also to provide clear structure and guidance as to how the whole puzzle fits together. It is often the case that “the details” make or break the success of a technology, and open architectures will allow us to define and set expectations more reliably while also defining data flows into and out of open systems taking into account privacy and security concerns. There are actually emerging examples of what open architectures might look like including ITANA’s draft Reference Architecture for Teaching and Learning. Similarly, open infrastructures will define the environments within which software is run making them more uniform over time.
In the distance, not nearly as far away in the future as it only recently was, open ecosystems will soon define how many products interact, interconnect, and behave at scale. Open ecosystems will exhibit many software products working together in tandem to create a more powerful whole. Predictions for this ecosystem might look like have already begun to materialize.
Open Content
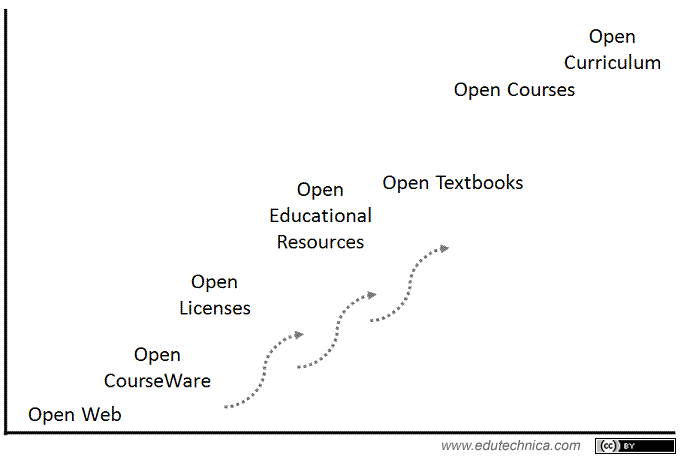
In tandem with how software has evolved in terms of openness over time, momentum behind open content has been building as well. Open content began with the open web, which in cyclical fashion is actually making a resurgence. Content on the open web is accessible to all, directly linkable, and can be found through search engines. There are no logins or other technical constraints enforced to view it. Some of the earliest major attempts at opening educational content can be categorized as open courseware – which put entire courses worth of material on the open web for everyone to view. Soon, it became apparent that while viewing course materials in an open manner was nice, there had to be better ways to reuse and repurpose the content. Given the constraints of copyright and fair use, open licenses created the legal structure within which to enable this. Once content was put on the open web and combined with these permissive licenses, it then became possible to create reusable groupings of content called open educational resources (or OERS) which took many forms. Sometimes an OER was a simple web page with a simple module or lesson. Other times an OER was much larger and encompassed a package of materials with graphics, video, and animation. OERs could be used in whole or part, combined with other OERs, or reworked altogether to fit a specific purpose. A framework emerged for defining openness of content in terms of ability to reuse, revise, remix, redistribute, and retain content.
Over time, largely driven by market forces, open textbooks emerged as packaged sets of OERs and wholly-commissioned works to replace the proprietary, copyrighted works of the traditional content publishers. While not completely different from OERs, they represent an attempt to create a complete set of materials and learning content for the scope of an entire course.
But perhaps the most game-changing recent development in open content has been the creation of the open course. And when I say open course, I don’t necessarily mean Massive Open Online Courses (or MOOCs) but all forms of courses that allow broad participation from many learners and faculty at many universities (and even just intellectually-curious individuals). Open courses in their many forms begin to break down the paradigms of the traditional course including timeframe, structure, who can participate, and to what end goal.
In the future, we will likely see whole curricula designed around open content. We see evidence of this through efforts that attempt to clearly define learning objectives, sequences, and outcomes for whole programs of study.
Content itself over time is also evolving to be much more dynamic and responsive to the individual user.
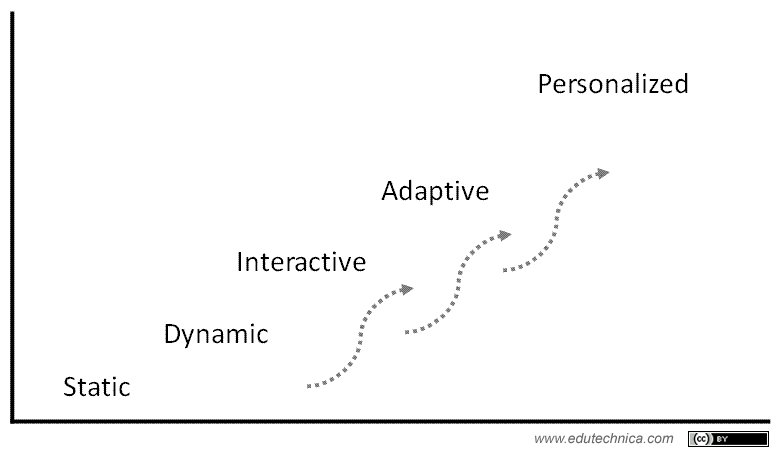
- Static content is straight “text on a web page”
- Dynamic content exhibits animations and video but is otherwise just static content in motion
- Interactive content can be manipulated by the user to display or behave or respond differently based on the nature of the interaction
- Adaptive content is able to display differently based on rule sets. These rule sets can be pre-defined for all users, or users can be grouped into “market segments” for the content to display /respond differently based on which “bucket” a user happens to fall into. Many systems are beginning to exhibit or support some form of adaptivity.
- We’re not quite there yet, but personalized content will focus on the individual with not only a very mature and refined understanding of his or her learning styles and prior learning but also taking into consideration longer-term learning and career goals.
Future Predictions
Because of this tendency for content itself to become more personalized, I see the evolution curves of both content and software becoming increasingly intertwined over time. Open courses in particular begin to bring the trajectories of open content and open software together in a way for large, broad sample sizes of users to help us to statistically validate (or alternatively capture more anecdotal evidence) about how to tailor content more appropriately to individual students.
One future possibility is that many instructors may collaborate to build a single, complete “master copy” of a course which can be syndicated and customized for an individual instructor’s use, sharing in the burden of creating, suggesting, and updating course materials. When used at scale, this “master course” may collect analytical data and human feedback from hundreds of institutions and suggest to other instructors which materials work best and in which order. Instructors may also add remedial materials for students who need reinforcement of key concepts and stretch materials for students who want to explore more – something that would be a significant amount of extra work for an individual professor.
Open continues to change the dynamics of education and will continue to do so into the future. Open should not be seen as a threat – but rather an opportunity maker. It will undoubtedly change the ways we collaborate, partner, and differentiate. I encourage everyone to see the possibilities and think creatively about what open enables. We can shape how things will materialize because of open, and by better understanding open I believe the better things will be.
This post written by George Kroner